文字コード
文字コードについて説明したページです。
文字の判定方法や、HTMLで推奨の文字コードなどについて説明しています。
文字コードとは
文字コードは、1つ1つの文字に対して数字を割り当てたものです。
例えば、ASCIIコードは、7ビットを使って以下のように割り当てています。
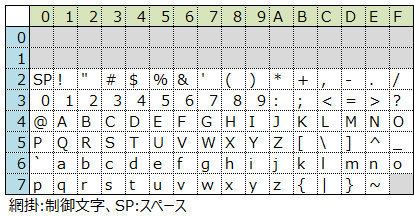
7ビットの内、上位3ビットは水色のように0〜7と表しています。2進数の000〜111(3ビット)が、16進数で0〜7になるためです。下位4ビットは薄緑のように0〜Fと表しています。
表の見方としては、例えば「A」は41が割り当てられています。メモ帳などで保存すると、この数字が保存されます。ASCIIコードは、英数字や一部記号が扱えますが、平仮名や漢字は扱えません。詳細は、「ASCIIコード表」をご参照下さい。
ASCIIコードに似た文字コードとして、EBCDICコードがあります。EBCDICコードで「A」は16進数のC1です。このため、ASCIIコードで保存したファイルは、EBCDICコードを使う機器で開くと異なる文字になってしまいます。
ISO-2022-JP(JISコード)
ISO-2022-JPは、平仮名や漢字も使える日本語向け文字コードです。ASCIIコードと同じ7ビット、もしくは8ビットを使っています。7ビットだとASCIIコードと同じ文字数しか扱えませんが、エスケープシーケンスによって扱える文字を増やしています。
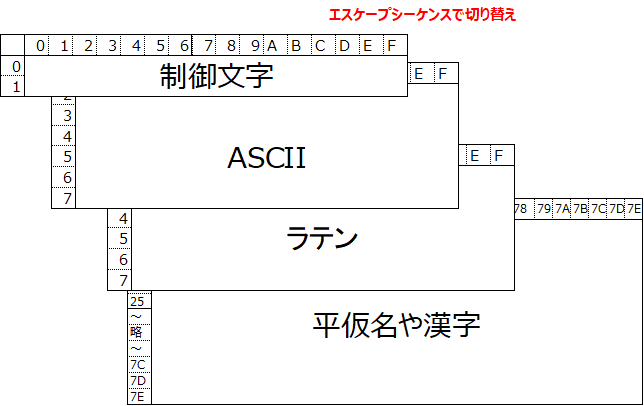
エスケープシーケンスで扱える文字を切り替えますが、切り替えて使える文字範囲(上図の箱1つ1つ)を文字集合と言います。使えるエスケープシーケンスとその16進数、対応する文字集合の例は、以下の通りです。
| エスケープシーケンス | 16進数 | 文字集合 |
|---|---|---|
| ESC ( B | 1B 28 42 | ASCII |
| ESC ( J | 1B 28 4A | ラテン文字 |
| ESC $ B | 1B 24 42 | 平仮名や漢字 |
例えば「test」という文字列は、コードが「74 65 73 74」になります。これは、ASCIIコードと同じです。ASCIIコードの範囲だけであればエスケープシーケンスを使わなくて済みます。これにより、他のASCII互換の文字コードで保存したファイルでも、英数字だけであれば文字化けしません。
また、平仮名や漢字は7ビットでは不足するため、7ビット+7ビット(もしくは8ビット+8ビット)で表現します。このように、1バイト(8ビット)で表せない文字を、マルチバイト文字と呼びます。
例えば、「漢字test」という文字列は「1B 24 42 34 41 3B 7A 1B 28 4A 74 65 73 74」になります。
赤字部分(1B 24 42)が平仮名や漢字を使うためのエスケープシーケンス、青字部分(1B 28 4A)がラテン文字を使うためのエスケープシーケンスです。ラテン文字はASCIIとほとんど同じですが、「\」が「\」になるなど少し違いがあります。つまり、日本語環境向けです。「漢」は34 41、「字」は3B 7Aでマルチバイト文字です。
Shift_JIS
Shift_JISも、平仮名や漢字が使える日本語向け文字コードです。Shift_JISでは、ASCIIコードを拡張して8ビットを使い、半角カナが扱えるようにしています。
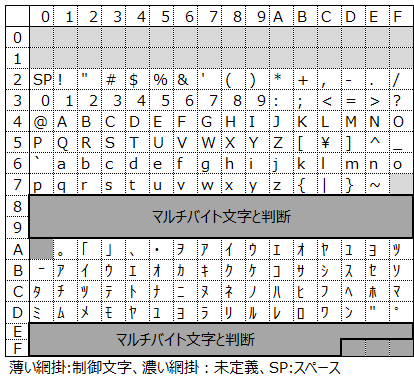
太枠の部分は、この数字が1バイト目に現れるとマルチバイト文字と識別します。例えば、82 A0は1バイト目の82が太枠内のため、マルチバイト文字と判断でき、2バイト目のA0との組み合わせで「あ」となります。
ISO-2022-JPでは、マルチバイト文字の領域は1バイト目が21〜7Eでしたが、ASCIIコードと重複しています。例えば、21であれば「!」が該当します。これが「!」なのか、マルチバイト文字なのか区別するためにエスケープシーケンスが必要でした。
Shift_JISでは、マルチバイト文字の1バイト目を未定義部分にズラして(シフトして)使うようにしています。このため、マルチバイト文字との区別にエスケープシーケンスを必要とせず、ASCIIコードとの互換もあります。
Shift_JISは、日本語のMS-DOSで採用された事から利用率が高く、日本語を使うHTML文書の文字コードとしても広く使われていました。
EUC-JP
EUC-JPも、平仮名や漢字が使える日本語向け文字コードです。基本的な考え方は、Shift_JISと同じです。但し、半角カナは2バイトで表現されています。
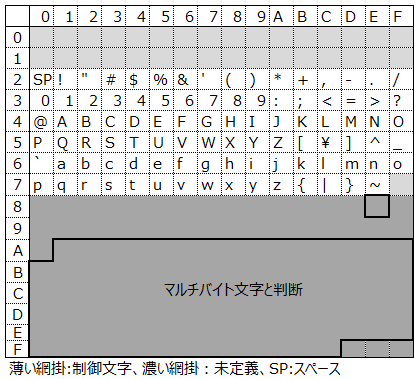
太枠部分の数字がマルチバイト文字の1バイト目を示します。例えば「あ」の文字コードは、A4 A2となります。
8E部分は半角カタカナ用で、8E A1〜8E DFまで割り当てられています。
EUC-JPはUNIX機で採用されたことから、パソコンとUNIX機の間でテキストファイルを交換した際は、文字コードを変換する必要がありました。
Unicode
これまで説明してきた文字コードは、ASCIIを除いて日本語向けです。ISO-2022-KR、EUC-KR(共に韓国語)などそれぞれの言語向けに文字コードがあります。
Unicodeは、それぞれの言語でバラバラだった文字コードを、1つの文字コードで表現できるように作られました。Unicodeで代表的なのは、UTF-8とUTF-16です。
- UTF-8
- 1〜4バイトで文字を表します。つまり、文字コードは8ビット(1バイト)単位に可変です。00〜7FまではASCIIコードと同じで、80以降は2〜4バイトのマルチバイト文字用です。このため、ASCII互換があります。
- UTF-16
- 2バイトか4バイトで文字を表します。つまり、文字コードは16ビット(2バイト)単位に可変です。例えば、「A」は2バイト使って00 41となるため、ASCII互換がありません。(00が余計)
最近のHTMLでは、UTF-8が推奨されています。これは、ASCII互換でないと、文字コードの指定を読み取れない可能性があるためです。UFT-8であれば、言語が違う環境であっても、文字化けせずに表示できる可能性があります。
したがって、これからのHTML文書で文字コードを指定する時は、UTF-8がお薦めです。文字コードをUTF-8にするためには、head要素内で<meta charset="utf-8">と記述します。